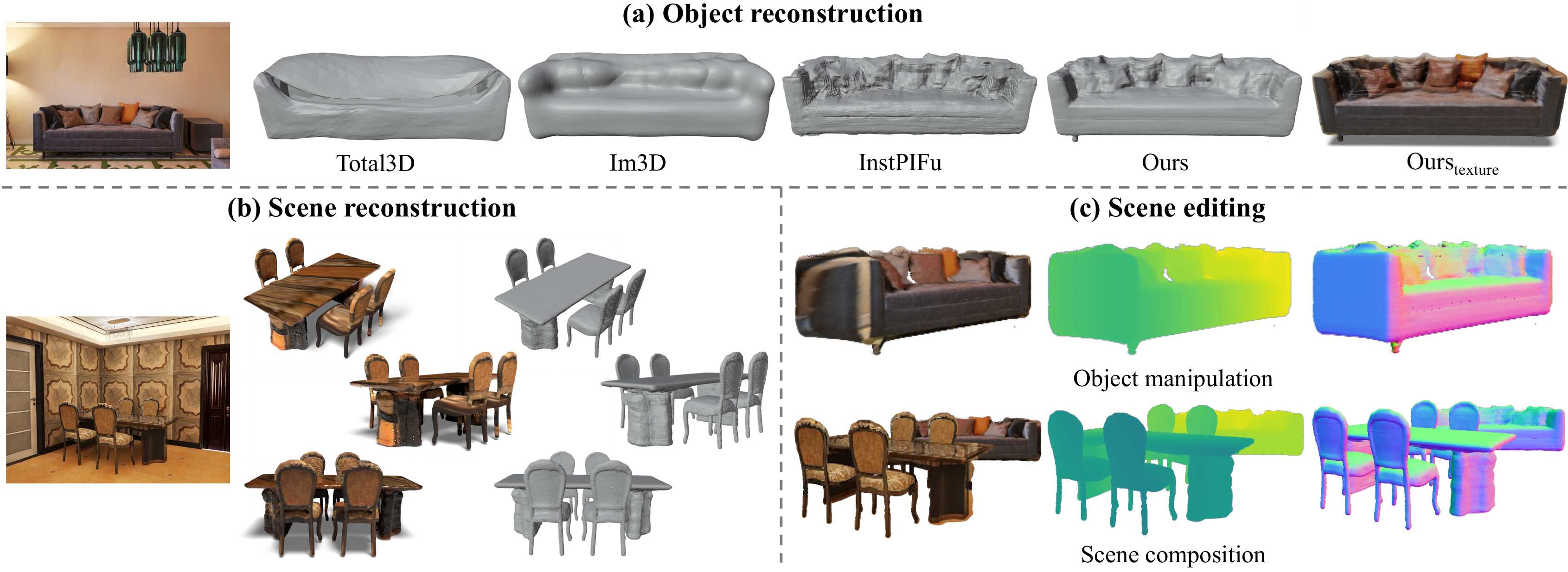
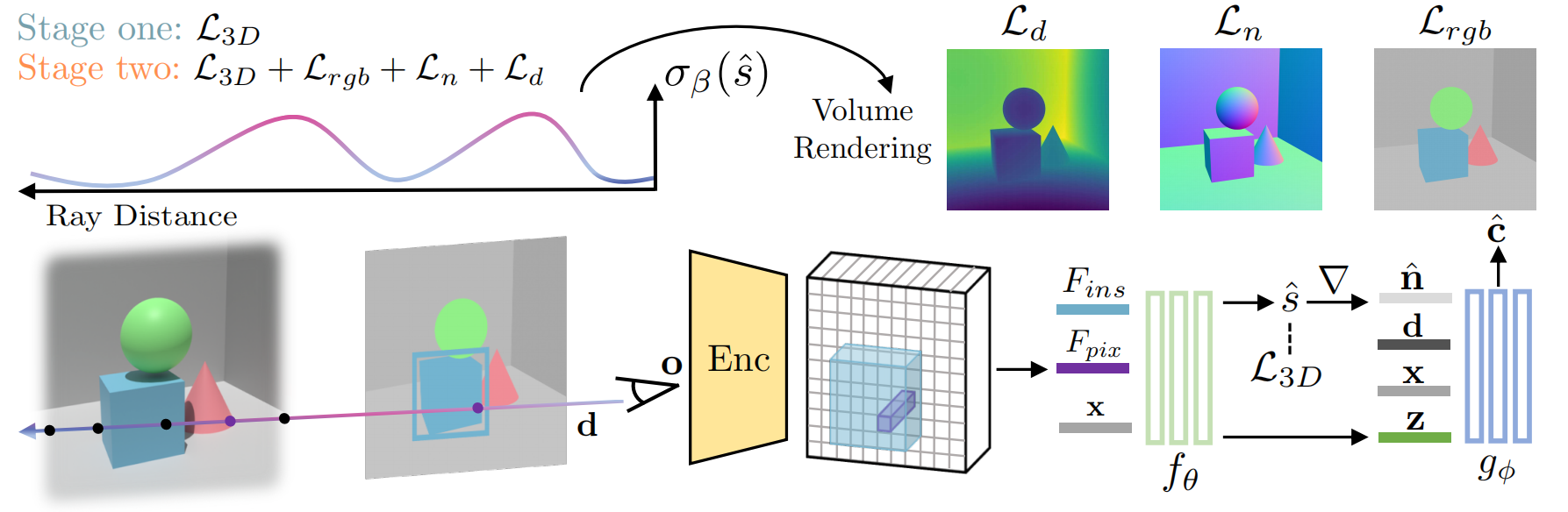
Reconstructing detailed 3D scenes from single-view images remains a challenging task due to limitations in existing approaches, which primarily focus on geometric shape recovery, overlooking object appearances and fine shape details. To address these challenges, we propose a novel framework for simultaneous high-fidelity recovery of object shapes and textures from single-view images. Our approach utilizes SSR, Single-view neural implicit Shape and Radiance field representations, leveraging explicit 3D shape supervision and volume rendering of color, depth, and surface normal images. To overcome shape-appearance ambiguity under partial observations, we introduce a two-stage learning curriculum that incorporates both 3D and 2D supervisions. A distinctive feature of our framework is its ability to generate fine-grained textured meshes while seamlessly integrating rendering capabilities into the single-view 3D reconstruction model. This integration enables not only improved textured 3D object reconstruction by 27.7% and 11.6% on the 3D-FRONT and Pix3D datasets, respectively, but also supports the rendering of images from novel viewpoints. Beyond individual objects, our approach facilitates composing object-level representations into flexible scene representations, thereby enabling applications such as holistic scene understanding and 3D scene editing.
Our approach utilizes neural implicit shape and radiance field representations, leveraging explicit 3D shape supervision and volume rendering of color, depth, and surface normal images. To overcome shape-appearance ambiguity under partial observations, we introduce a two-stage learning curriculum that incorporates both 3D and 2D supervisions. Please refer to our paper for more details or checkout our code for implementation.
We compare our reconstruction with state-of-the-art models in single-view 3D reconstruction. Our model produces textured 3D objects with smoother surfaces and finer details compared to previous methods.





We compare our model with generative models that demonstrate potential zero-shot generalizability by leveraging 2D or 3D geometric priors learned from large-scale datasets. Please refer to our paper for a more in-depth discussion.










Scene reconstruction results on SUN RGB-D. Note that our model is only trained on FRONT3D. The results demonstrate that our method can reconstruct detailed object shapes and intricate textures in real images with cross-domain generalization ability.






Here we show our model's rendering capabilities, to render the color, depth, and normal images through volume rendering from the single-view input image, even when the viewing angles change significantly.












We demonstrate our model's potential in representing scenes and enabling 3D scene editing applications.














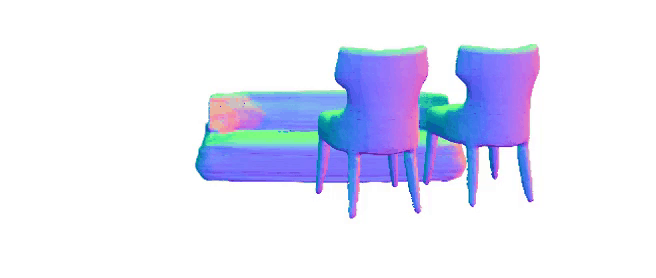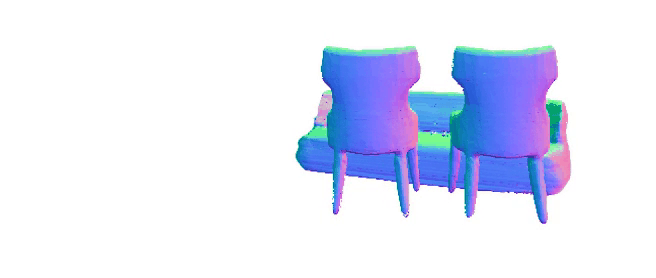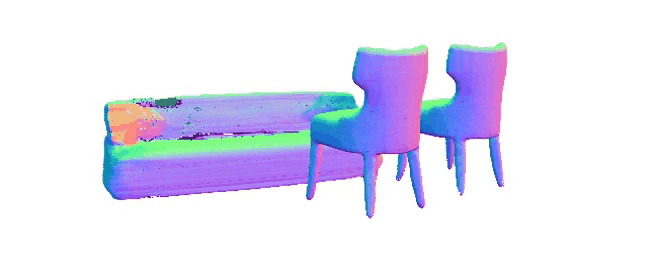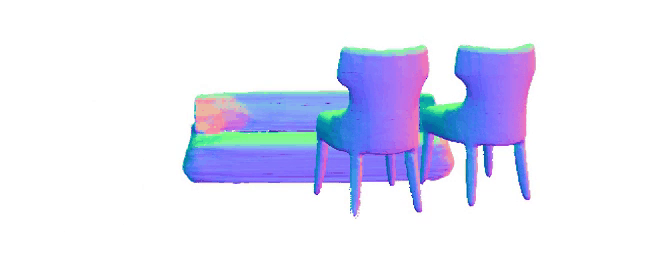
Holistic 3D Scene Parsing and Reconstruction from a Single RGB Image
Total3DUnderstanding: Joint Layout, Object Pose and Mesh Reconstruction for Indoor Scenes from a Single Image
Holistic 3D Scene Understanding from a Single Image with Implicit Representation
Towards High-Fidelity Single-view Holistic Reconstruction of Indoor Scenes
Shap-E: Generating Conditional 3D Implicit Functions
Zero-1-to-3: Zero-shot One Image to 3D Object
@inproceedings{chen2023ssr,
title={Single-view 3D Scene Reconstruction with High-fidelity Shape and Texture},
author={Chen, Yixin and Ni, Junfeng and Jiang, Nan and Zhang, Yaowei and Zhu, Yixin and Huang, Siyuan},
booktitle=ThreeDV,
year={2024}
}